
機械学習とPythonの勉強がてら、kaggle常設コンテストのspaceTitanicに参加してみた。
ドメイン知識による有利不利が関係ないので簡単そう 見慣れない奇抜な題材で面白そうなので、参加してみるとことにした。
kaggle、Pythonについては初心者なので、間違い、不適切な考察があるかもしれないのでご了承を。

コンテスト概要
2912年(タイタニック号が出航してから1000年後)、宇宙船タイタニック号が13,000人の乗客を乗せていた。乗客らは、太陽系から近隣の居住可能な太陽系外惑星へ移住しようとしてる。
その航海中、宇宙船タイタニック号は時空の歪みに衝突したことで、乗客のほぼ半数が異次元に転送された。
今回は、与えられるデータを基に、乗客が異次元に転送されたら否かを予測することが目的となる。
与えられるデータ
- PassengerId
それぞれの乗客に対して一意の番号が割り振られている。IDはgggg_ppの形式となっており、ggggはグループを示す。ppはグループの人数を示す。なお、グループのメンバーは家族であることが多いが、必ずしもそうであるとは限らない。 - HomePlanet
乗客の出発した惑星。基本的に彼らの居住地となっている。(Earth、Europa、Marsのどれかに属する。) - CryoSleep
乗客が、航海中に冷凍睡眠をしているか。冷凍睡眠中の乗客は客室に閉じ込められる。 - Cabin
どの客室にいるかを示す。Cabinはdeck/num/sideの形式をとる。sideの、PはPort(進行方向に対して左側のこと)、SはStarbord(進行方向に対して右側のこと)を示す。 - Destination
乗客の目的地(TRAPPIST-1e、55 Cancri e、PSO J318.5-22のどれかに属する。) - Age
乗客の年齢 - VIP
乗客が特別VIPサービスにお金を払っているかを示す - RoomService, FoodCourt, ShoppingMall, Spa, VRDeck
タイタニック号の豪華施設にどれほどの金額を使ったかを表す。 - Name
乗客の氏名 - Transported
乗客が異次元に転送されたかを表す。今回、予測する目標となる項目である。
データの特徴
2912年の宇宙船事故による異次元転送の有無なんて、何が因子か見当もつかないので、とりあえず何が関係がありそうか見てみる。
とりあえず、以下のようにデータ処理に必要そうなライブラリをインポートして、各種データを見てみた。
import seaborn as sns
import numpy as np
import pandas as pd
import math
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
dataset=pd.read_csv("/kaggle/input/spaceship-titanic/train.csv")年齢別転送数
sns.histplot(x="Age",hue="Transported",data=dataset)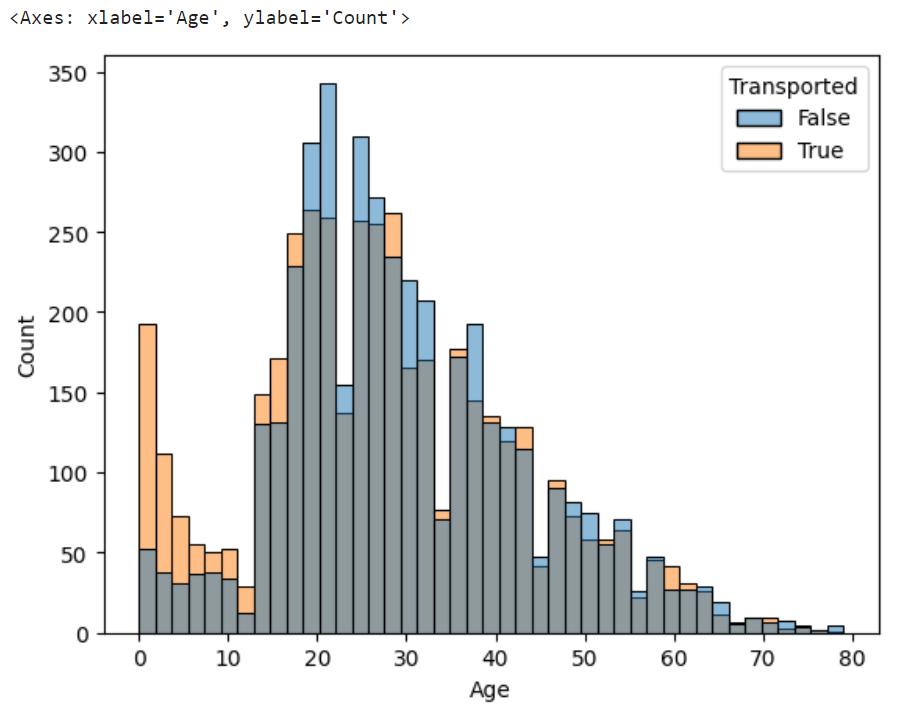
どうやら10代は転送されていることが多く、20歳前後はやや転送させないことが多い。
それ以外の年代については、あまり年齢と転送数に大きな関係はなさそう。
VIP別転送数
sns.countplot(x="VIP",hue="Transported",data=dataset)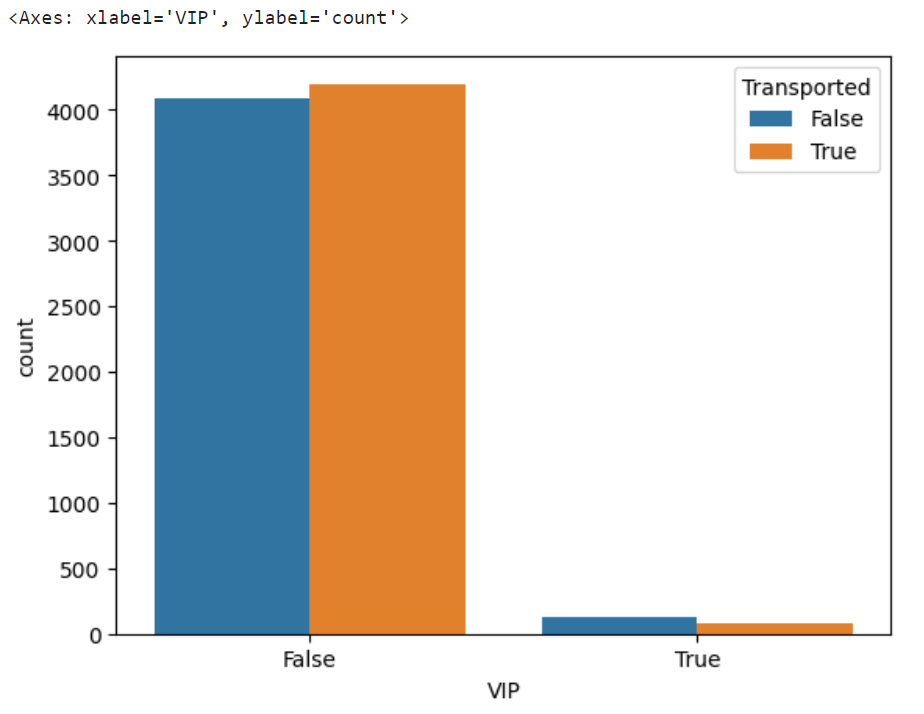
VIPだろうとそうでなかろうと、あまり転送に影響を与えることはなさそう。
VIP会員は人数が少ないのでわかりづらいが、転送された人:転送されていない人は180:222となっており、これもあまり大きな関係はなさそう。
目的地別転送数
sns.countplot(x="Destination",hue="Transported",data=dataset)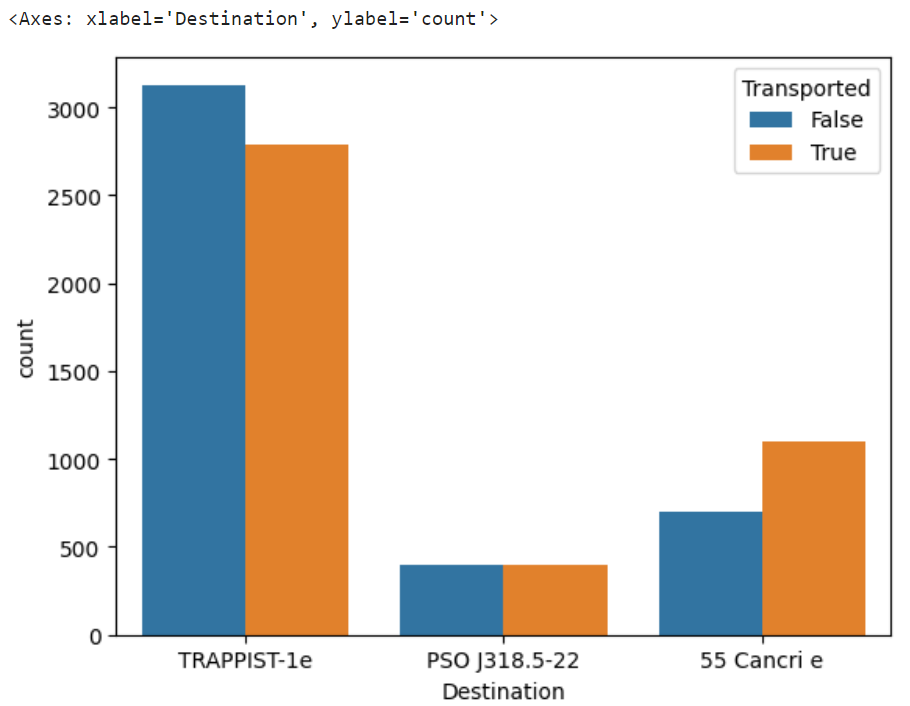
目的地が、55 Cancri eの乗客が転送される割合がやや高めであることが判明。
TRAPPIST-1eについては、わずかに転送されにくそう。
出発地別転送数
sns.countplot(x="HomePlanet",hue="Transported",data=dataset)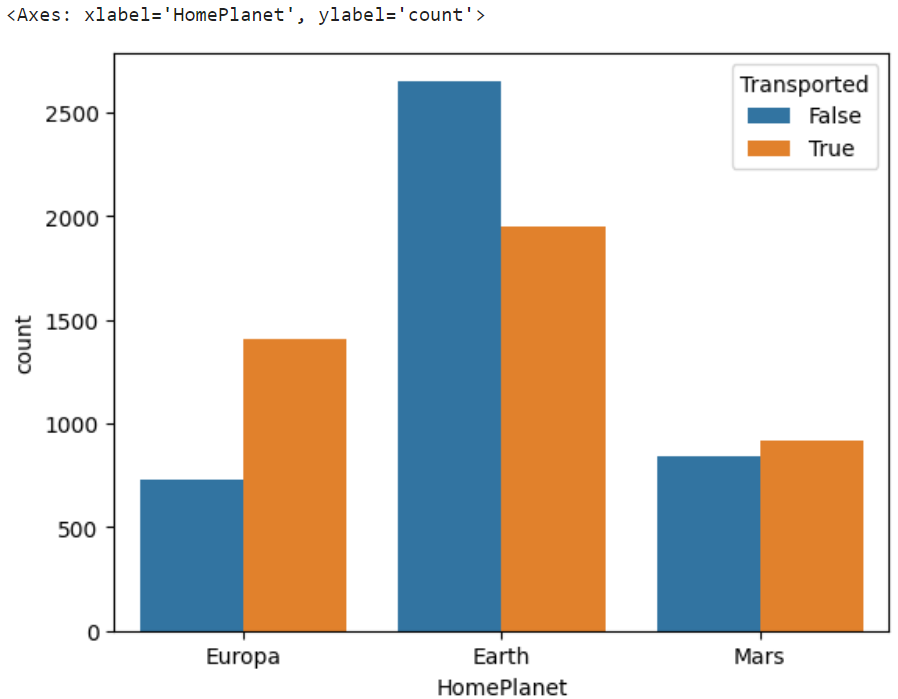
出発する惑星によっても転送数に差がでることがあることが、判明。
ほむほむ( ˘ω˘)…
特徴量エンジニアリング
Cabin列は、1列にdeck/num/sideと3つの要素が入っているので、このままでは極めて扱いづらい。これをdeck、num、sideの3列に分けて、データ処理に使いやすい形に変換する。
次に、RoomService, FoodCourt, ShoppingMall, Spa, VRDeckの合計使用金額とグループ人数を追加した。最後に今回の予測に名前は使用しないので、名前列を削除する。
Cabin列について
CabinDeck,CabinPortについては、とりあえず欠損値をXXとして、CabinNumについては欠損値を-1として設定し、グラフを見てみる。
df=dataset.assign(CabinDeck="XX").assign(CabinNum=-1).assign(CabinPort="XX")
for index,row in df[::].iterrows():
cabin = str(row["Cabin"]).split("/")
if(len(cabin)!=3):
continue
for i in range(3):
df.iat[index,14+i]=cabin[i]CabinDeck
sns.countplot(x="CabinDeck",hue="Transported",data=df)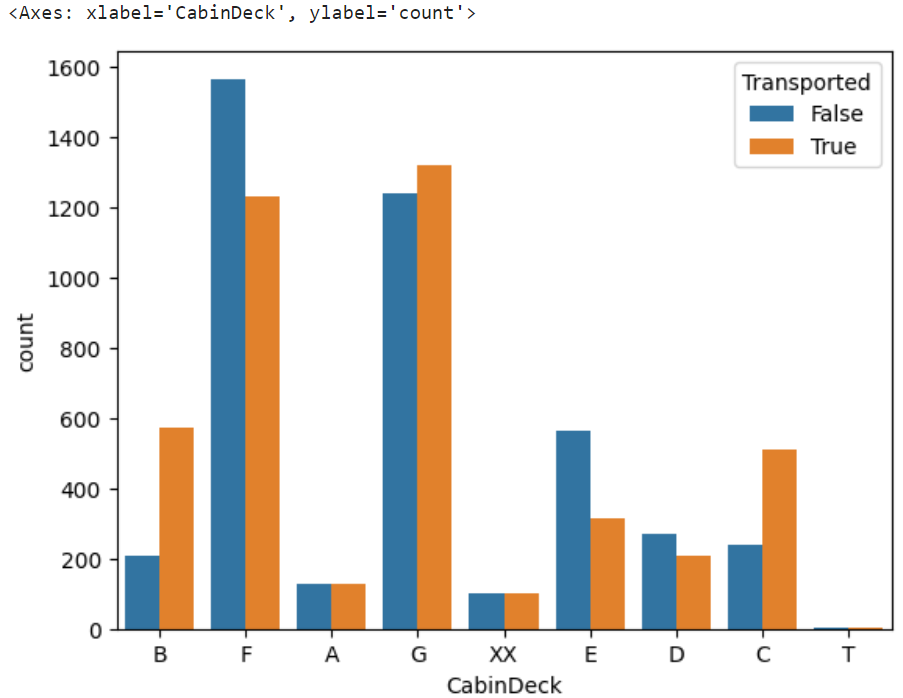
各CabinDeck間で転送率に差があることが分かった。また、TDeckの乗客数が極端に少ないことも分かった。
CabinDeckの欠損値を最頻値(つまり、F)で補完してしまうと、欠損している客室が実はBだった時に上手く予測できない。このため、欠損値を示すXXのままにしておく。
なお、Tは極端にデータ数が少なく、残しておくと不均衡データが発生する要因となることから、Tは転送率の差が小さいAに置換する。
df.loc[df["CabinDeck"]=="T","CabinDeck"]="A"CabinNum
df["CabinNum"]=df["CabinNum"].astype(int)
sns.histplot(x="CabinNum",hue="Transported",data=df)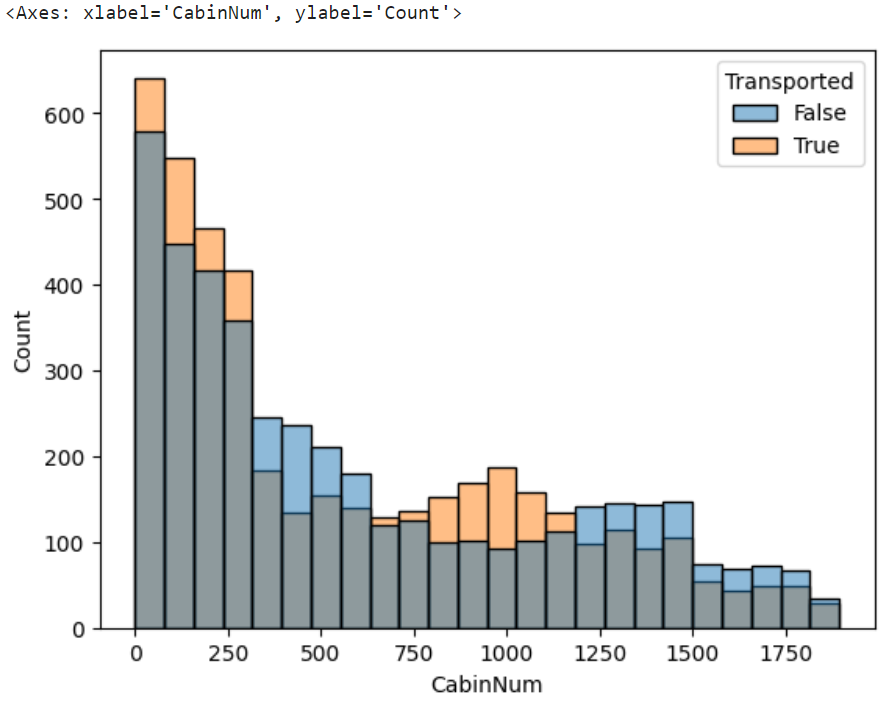
客室番号によっても差が転送率に差が生じることが判明。
欠損値は最も転送率に差がなさそうな625で補完する。
df.loc[df["CabinNum"]==-1,"CabinNum"]=625CabinPort
sns.countplot(x="CabinPort",hue="Transported",data=df)
Portによって転送率に差があることが判明。欠損値XXを無理にPかSのどれかに属させると精度悪化につながる可能性があるので、これはこのままにしておく。
合計使用金額について
RoomService, FoodCourt, ShoppingMall, Spa, VRDeckの欠損値処理については、特別な処理を行った。欠損していない他のどの項目で1円も使っていない場合、どの施設も使用していないと考えられる。一方、何かしらの施設を使用している場合は、欠損している項目についても使用していると考えられる。
このため、欠損値以外の要素がすべて0ならば、欠損値を0に、それ以外は、0を除く中央値で欠損値処理を行った。
この様な欠損値処理をした上で、新規にTotalCost列を用意し、RoomService, FoodCourt, ShoppingMall, Spa, VRDeckの合計値を代入する。
MedianData=dataset.iloc[:,7:12].replace(0,float("nan")).median()
for index, row in df.iterrows():
if row["RoomService"]>0 or row["FoodCourt"]>0 or row["ShoppingMall"]>0 or row["Spa"]>0 or row["VRDeck"]>0:
df.iloc[index,:]=row.fillna(MedianData)
else:
df.iloc[index,7:12]=0
df["TotalCost"]=df["RoomService"]+df["FoodCourt"]+df["ShoppingMall"]+df["Spa"]+df["VRDeck"]sns.histplot(x="TotalCost",hue="Transported",data=df)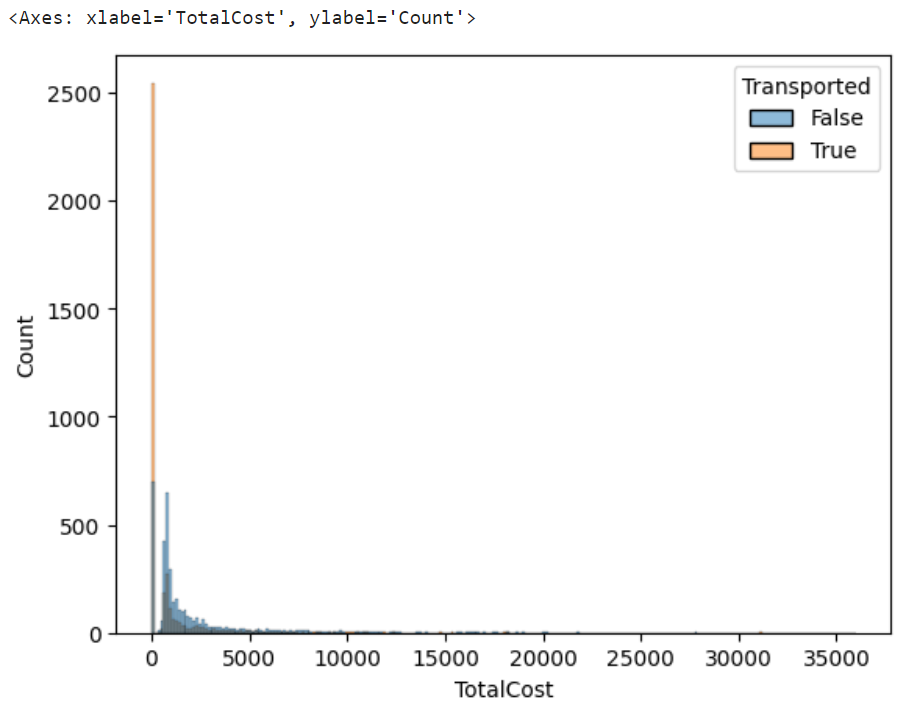
船内施設を全く使わない人よりも、何か使っている人の方が転送されにくいことが判明。顕著に差が生じており、なかなかいい感じ。
グループ人数について
trainデータとtestデータを組み合わせて、乗客IDとグループ人数をまとめたデータフレームを作成する。
testdata=pd.read_csv("/kaggle/input/spaceship-titanic/test.csv")
groupdf=pd.DataFrame(pd.concat([df,testdata])["PassengerId"])
groupdf["GroupSize"]=0
size=0
for index,row in groupdf[::-1].iterrows():
if size==0:
size=int(str(row["PassengerId"]).split("_")[1])
groupdf.iloc[index-size+1:index+1,1]=size
size=size-1
df=df.merge(groupdf,on="PassengerId")sns.countplot(x="GroupSize",hue="Transported",data=df)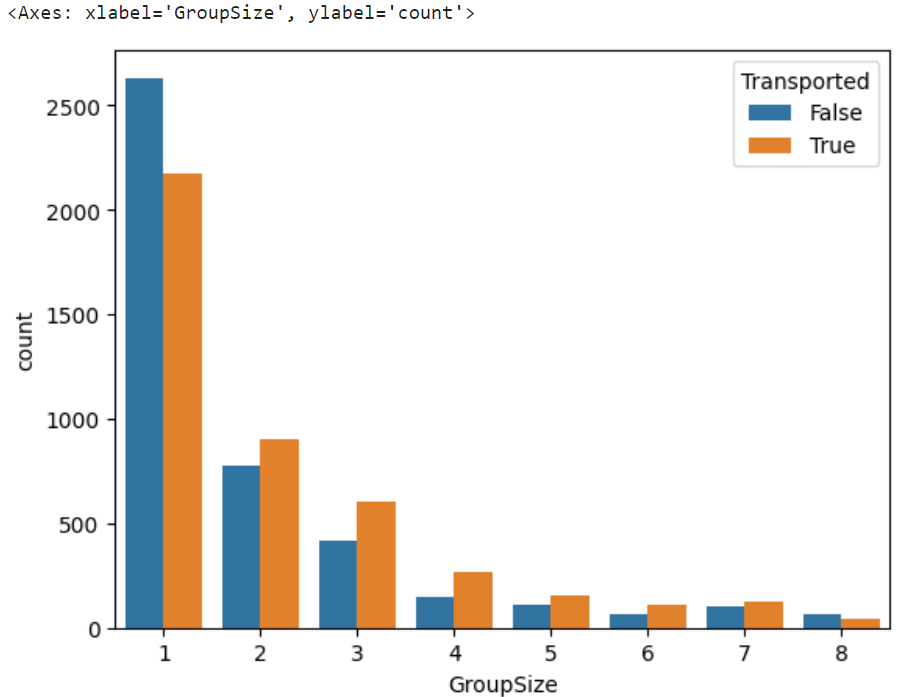
グループ人数が多い程、転送される割合が多いことが判明。
名前列削除について
名前が転送可能性に関与について、検証をしていないので安易に名前を削除してしまうのは、よろしくないかもしれない。しかしながら、普通に考えて転送するか否かは名前と関係がなさそうなので、列を削除した。
df=df.drop("Name",axis=1)
df=df.drop("Cabin",axis=1)
df=df.drop("PassengerId",axis=1)その他、必要のない列を削除している。
欠損値処理
trainデータには欠損値が存在する。データを見る限り、転送についての決定的な要素はなかったと考えられるため、今回は深く考えず、年齢の欠損値は中央値で、VIPや目的地等カテゴリデータについては最頻値で処理を行った。
df=df.fillna({"Age":dataset["Age"].median()})
df=df.fillna(df.mode().iloc[0])ダミー変数処理
カテゴリ変数をOne-hotエンコーディングする。この際、多重共線性の発生を防ぐために、ダミー変数を1列だけ削除したい。
drop_firstを有効にすると、CabinDeck_Aが削除されてしまい、欠損値を示すCabinDeck_XXは残ってしまう。このため今回、drop_firstによる削除をせず、明示的に欠損値を示すカテゴリデータを削除する。
df=df.astype({"CabinNum":int})
finaldf=pd.get_dummies(df, drop_first=False)
finaldf=finaldf.drop(["CabinPort_XX","CabinDeck_XX"],axis=1)学習
今回は、SVMで学習させる。実行するたびに成績が変化すると困るので、パラメータについては、random_state=1としている。
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
X=df.drop(columns="Transported")
Y=df["Transported"]
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=1)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# SVMモデルの設定
svm = SVC(kernel='rbf', random_state=1)
# k分割交差検証
k = 5 # 分割数
scores = cross_val_score(svm, X_train, y_train, cv=k, n_jobs=-1)
# 平均精度の表示
print(f'Average accuracy across {k} folds: {scores.mean()}')
# モデルのトレーニング
svm.fit(X_train, y_train)
# テストセットでの評価
y_pred = svm.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Test set accuracy: {accuracy}')Average accuracy across 5 folds: 0.798100740112439
Test set accuracy: 0.8016101207590569
予測
以下のコードでtestデータを変形させ、先ほど作成した分類機で予測させた。
testdata=testdata.assign(CabinDeck="XX").assign(CabinNum=625).assign(CabinPort="XX")
for index,row in testdata[::].iterrows():
cabin = str(row["Cabin"]).split("/")
if(len(cabin)!=3):
continue
for i in range(3):
testdata.iat[index,13+i]=cabin[i]
testdata.loc[testdata["CabinDeck"]=="T","CabinDeck"]="A"
for index, row in testdata.iterrows():
if row["RoomService"]>0 or row["FoodCourt"]>0 or row["ShoppingMall"]>0 or row["Spa"]>0 or row["VRDeck"]>0:
testdata.iloc[index,:]=row.fillna(MedianData)
else:
testdata.iloc[index,7:12]=0
testdata["TotalCost"]=testdata["RoomService"]+testdata["FoodCourt"]+testdata["ShoppingMall"]+testdata["Spa"]+testdata["VRDeck"]
testdata=testdata.merge(groupdf,on="PassengerId")
testdata=testdata.drop("Name",axis=1)
testdata=testdata.drop("Cabin",axis=1)
testdata=testdata.drop("PassengerId",axis=1)
testdata=testdata.fillna({"Age":dataset["Age"].median()})
testdata=testdata.fillna(testdata.mode().iloc[0])
testdata=testdata.astype({"CabinNum":int})
testdata=pd.get_dummies(testdata, drop_first=False)
testdata=testdata.drop("CabinDeck_XX",axis=1)
testdata=testdata.drop("CabinPort_XX",axis=1)testdata1=scaler.fit_transform(testdata)
pred=rfc.predict(pd.DataFrame(testdata1))結果
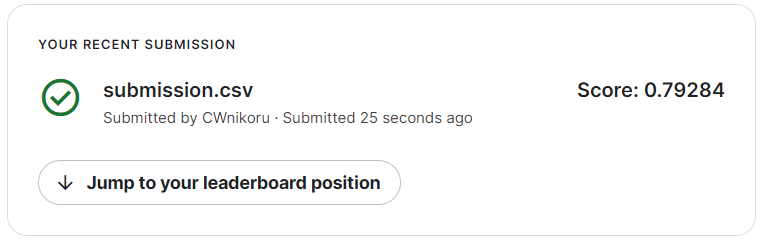
以下のコードで適当に提出ファイルとしてふさわしい形に変換し、提出した。
predd=pd.DataFrame({"Transported":pred})
tmp=pd.read_csv("/kaggle/input/spaceship-titanic/test.csv")
predd.assign(PassengerId=0)
predd["PassengerId"]=tmp["PassengerId"]
predd=predd.reindex(columns=['PassengerId', 'Transported'])
predd.to_csv("submission.csv", index = False)コンテスト参加者全体で半分よりは上で、初心者にしてはかなりいい成績を出すことができた。
次回は、更に予測精度を高めるため、SVMのハイパーパラメータの最適化を行う。

コメント